
At Neo.Tax, we often talk about the value of “contemporaneous data” when filing for R&D tax credits. As evidenced by the Kyocera case and the proposed changes to Form 6785, the IRS has signaled a desire for contemporaneous data and more granular evidence in order to qualify for the credit. That’s why Neo.Tax’s ability to integrate with Jira and Linear data is such a game-changer: by coupling this data with advanced AI models, we can analyze it at scale to generate all of the outputs for an R&D credit filing, no matter the size of the business.
But while many AI-powered companies like to sell the magic of their products, our view is the opposite: tax is too high-stakes for faith; we need to show you exactly how our AI models work.
Introduction
One of the most important inputs into the R&D Tax Credit is an accounting of how much of each person’s time at the company was spent on qualified research activities, as defined by the IRS’s 4-Part Test.
At Neo.Tax, we use ticketing data from providers such as Jira and Linear to provide us with contemporary documentation that tracks which employees worked on which tasks.
This data source has several key advantages.
- First, it is contemporaneously generated during the normal course of work. As a result, it is much less likely to suffer from recall bias, as opposed to asking employees to recall their work history (often long) after the fact.
- Second, this data source is not maintained specifically for the R&D credit, and is therefore far less likely to be strategically manipulated.
Both of these features of ticketing data make it ideally placed to match the IRS’s guidance on the preferred documentation for the R&D credit. Per §1.41-4(d), “A taxpayer claiming a credit under section 41 must retain records in sufficiently usable form and detail to substantiate that the expenditures claimed are eligible for the credit.” Additionally, based on analysis of two court cases (Eustace v. Commissioner, 570 F.3d 672 (5th Cir. 2009) and Fudim v. Commissioner, T.C. Memo. 199-235), the IRS requires convincing evidence to prove qualified research expenses.
Because tickets are the product of engineers and researchers logging their own work, they may vary in the consistency and comprehensiveness of their record-keeping. At Neo.Tax, we use a proprietary AI model trained on a vast library of tickets to account for this, and automatically detect and correct any record-keeping inconsistencies.
Approach
We follow a two-step process. First, the AI model estimates a weight for each ticket. Next, we aggregate the weights to estimate the amount of time spent on each ticket.
The weight assigned to a ticket is proportional to its observed duration. For each ticket, we observe a signal of its start date and its end date. This gives us a baseline estimate Δ_ _for the number of days that were spent on the task described in the ticket.
We account for potentially inconsistent record-keeping by using an AI model to estimate a weight that adjusts the raw estimate according to the data quality. That is, given our model _f _(.) and a set of relevant input features χ, we can obtain a set of predicted weights Tikpd_ , which is the weight assigned to the ticket **_i** belonging to project p for contributor k on business day **d**, according to the following formula:
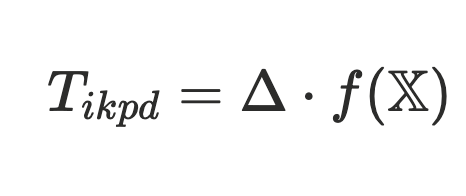
The model is trained on a large dataset of real-world tickets, with human-generated labels that tell us the amount of time that someone actually spent on a ticket. This model is then able to learn patterns in the types of mistakes that people may make when maintaining tickets and can determine by how much to correct the raw estimate Δ_ _based on the specific features of the ticket.
In the case where the record-keeping is highly consistent, then the ticket weights are simply a measure of how much time was spent on the task.
Then, we calculate effort Epk_ _on an annual basis for each contributor. Effort is measured as a percentage of the contributor’s time in the period that was spent on a particular project.
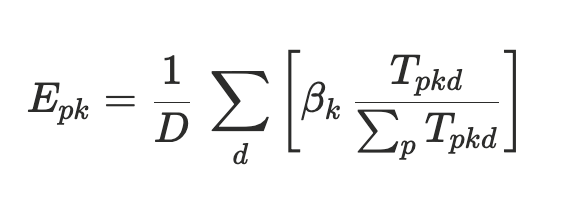
Where:
- βκ is a contributor-specific factor that accounts for the relationships between tasks
- D is the number of business days in the period
- In case all the weights T are zero, then ∑_ _is also zero.
What the Algorithm Looks Like In Practice
To see how the algorithm is constructed is one thing. But, what does it look like in action?
Example 1: Measuring effort from the observed ticket data
Stacy creates a ticket on February 12, 2024. On February 14th she opens a pull request in GitHub, which automatically marks the ticket as “In Progress” in Linear. On February 23rd, her pull request as approved and merged, which marks the ticket as “Complete.” This is the only ticket that she was working on during this period. Stacy will be assigned 8 days of effort for this ticket, because there are 8 business days between when the ticket started (on February 14th) and when it was completed (February 23rd), inclusive of the start and end dates.
Example 2: How does the AI account for human error?
John creates a ticket on March 12, 2023. On March 13th, he marks it as “In Progress,” but during stand-up it is decided that this task is no longer relevant, and therefore he will not do any work on it. He closes the ticket and marks it as complete on March 15, 2023.
The company’s internal policy is to mark work that was skipped as “Cancelled” in the resolution field in the Jira. However, John is a new employee and wasn’t aware, so he updates the status field to say “Won’t Do.”
Neo.Tax’s AI model will scan all of the ticket’s information and discern the intended meaning, even if the data has not been entered in the expected format. In this case, the ticket weight will be 0 because the status field indicates that no work was done on the ticket.
Why Share This Information?
You may be asking yourself: why are they sharing their algorithm? The answer is: we believe that, in tax, “it just works” is not enough for the savvy consumers we’re after. We need to pull back the curtain, because tax teams and accountants are diligent and need to be able to understand the how as well.
If you read this and are confused, that’s understandable. Get in touch and let our team of data scientists and tax experts walk you through it. Neo.Tax is not a magic box that spits out an R&D filing; it’s a collection of algorithms built by tax experts to solve for the specifics of this tax moment at scale.